文章地址:http://arxiv.org/abs/2010.04159
代码地址:https://github.com/jiangxiluning/Deformable-DETR
问题
目标检测算法中充斥着许多需要人为手工设计的模块,比如 anchor 大小,比例,生成策略,NMS,目标匹配策略等,导致目标检测算法不是完全端到端的。最近, DETR [^1] 提出了一种完全端到端的方法,通过结合 CNN 和 Transfomer, 利用匈牙利算法来解二部图匹配问题,取得了不错的效果。
不过 Detr 仍然有一些问题:1. 需要很多的 epoch 才能够收敛,获取跟其他目标检测器差不多的效果。2. 对于小目标性能不好。对于小目标一般检测器可以利用多尺度 feature map 进行融合,但是增大特征图会 Detr 的计算复杂度会呈指数级上升。
在初始化时候,注意力模块会给全部像素初始化一个复合均匀分布的注意力,随后模型需要在很大规模的像素点中学习稀疏的注意力,这使得收敛速度降低。
可以形变卷积在应该对稀疏空间数据上有天然的优势,但是它却不具备对关联的建模能力,这个能力是 Detr 模型之所以成功的关键所在。
贡献
- 将 Deformabale Conv 和 Self Attention 的核心能力相结合,形成 Deformable Attention Module,使得在建模关联能力的同时还能够大大减少不必要的计算量,且能够应对 Sparse Attention 的场景。
- 基于 Detr 这种完全的端到端检测模型,提出了 Iterative Bounding Box Refinement 机制和 Two-stage 的 Deformable Detr。
方法
Multi-head Attention
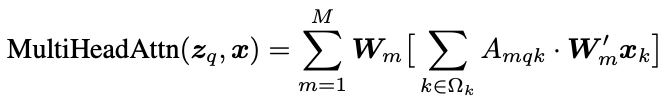
这个公式的计算复杂度为 $O(N_qC^2+N_kC^2+N_qN_kC)$,在 encoder 中输入是被拉成一维的特征图,所以 $N_q$ 和 $N_k$ 往往远大于 $C$,其复杂度又 $N_qN_kC$ 决定,它的复杂度是跟特征图大小是一个二次关系。
其次,由于在训练初期 $A_{mqk} \approx \frac{1}{N_k}$,由于输入跟图像大小相关 $N_k$ 会特别大,导致 $A_{mqk}$ 特别小,但是注意力又是稀疏的,所以会需要很长的训练周期来学习。
Deformable Attention Module
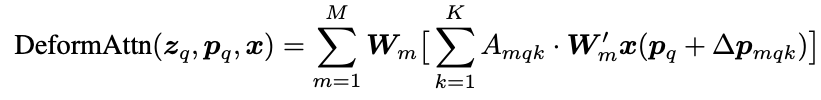
让我们首先回顾下,Deformable Conv 的操作,基于每个 $p_0$ 我们会在它附近采样固定距离的点 $p_n$, 再加上可形变能力,就是给每个 $p_n$ 加上一个偏移量 $\Delta p_n$, 这个 $\Delta p_n$ 是可学习的。
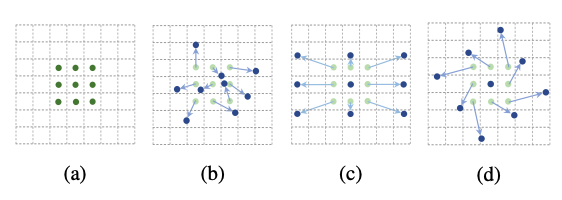
那么对于 Deformable Attention,我们也可以使用类似的操作,既然我们想要一个 sparse 的 attention,那么对于每一个待查询位置的特征 $z_q$ 它需要关注的位置应该要比 Dense Attention 的少,比如我们可以通过超参数 $K$ 来指定需要关注的点,针对每个位置 $p_q$ 我们需要学习 $K$ 个 $\Delta p_{mqk}$, 其中不同的 head 应该可以指定形变的形式,在论文中不同的 head 的 $\Delta p_{mqk}$ 被初始化为 8 领域的位置。为了在不同 $K$ 之间构建 attention,那我们需要使得 $\sum_k^K A_{mkq} = 1$。与一般的 Multi-head Attention 不同的是这里的 $\Delta p_{mqk}$ 和 $A_{mkq}$ 都是通过对 $z_q$ 做线性投影而得到的,这样也就将每个位置的查询特征 $z_q$ 和 attention 以及 offset 建立起了关联。
经过这样的改动整体的复杂度变为 $O(2N_qC^2+ \min(HWC^2, N_qKC^2))$,在 encoder 中 $N_q = HW$ 这个复杂度变为 $O(HWC^2)$,这个复杂度与 $HW$ 是线性关系而非二次关系。在 decoder 中 $N_q = N$,$N$ 为要解码的物体的个数,这个复杂度变为 $O(2NC^2+ NKC^2)$,与 $HW$ 无关。
Multi-scale Deformable Attention Module
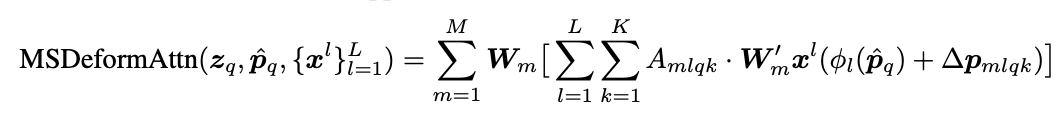
在理解了一般 Deformable Attention Module 的原理之后,加入 Multi-scale 就顺利成章了。在基础的 Deformable Attention 之上,基于每个查询点$\hat p_q$,我们可以定义 $LK$ 个偏移量 $\delta p_{mlqk}$,同样的 $\sum_k^K A_{mlkq} = 1$ 这样就在每个 scale 的 $K$ 个 key 之间构建 attention 关系,很好的将 scale 之间的信息交换引入进来。值得注意的是 $\hat{p}_q$ 是的范围是 $[0,1]$,其中 $\phi_l$ 是每个 scale 的坐标反函数,将 $\hat{p}_q$ 映射回实数域。
当 $L=1, K=1$ 并且 $\boldsymbol{W}_{m}^{\prime} \in R^{C_v \times C}$ 是单位矩阵时,Deformable Attention Module 可以退化为 Deformable Conv。Deformable Attention module 还可以看做是 Transformer Attention 的一种预筛选机制。
改动
Deformable Transformer Encoder
Detr 中的 Transformer attention 模块被 Multi-scale Deformable Attention 模块替换,$C_3$ 到 $C_5$ 加上通过最后的 $C_6$ ($C_5$ 1x1 卷积)作为多尺度特征图的输入,由于 Multi-scale Deformable Attention 可以在多个特征尺度之间做信息交换(Normalization),所以这里就不需要 FPN 了。
需要注意是,作者为了能够给每个 Scale 特征图一个显示的层信息,加入了层嵌入, ${e_l}^L_{l=1}$。
Deformable Transformer Decoder
在 decoder 中有两种 attention,一种是 self-attention,还有一种是 cross-attention。Cross-attention 中的 query 是定义好的物体向量,key 是 encoder 中输出的特征图。由于 deformable attention 是被设计用来处理卷积特征图的,作者只对 cross-attention 模块做了替换。
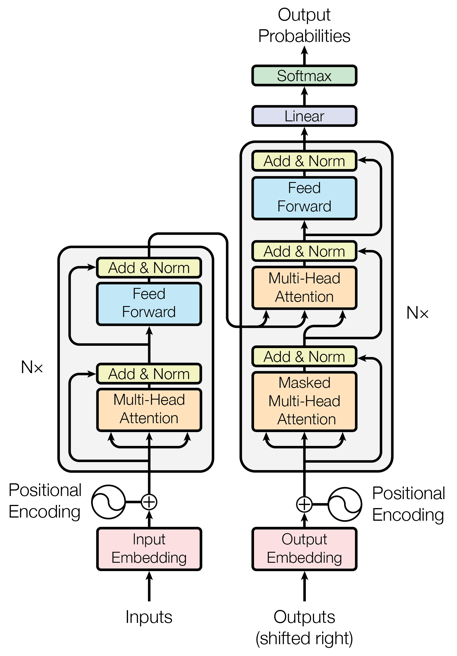
在最后 BBox 回归阶段,对于每个物体都会有一个 reference point,所以文章最后不是预测绝对左边,而是将 reference point 作为物体中心的初始猜测,然后基于这个点预测偏移量。这样通过优化,物体中心和 BBox 坐标被建立起来了联系,通过合适的训练最后会使得 BBox 预测更加准确,收敛更快。
Iterative Bounding Box Refinement
通过堆叠多个 Decoder,可以使得下层对上一层输出的 BBox 进行精修。 文章中精修的公式如下:
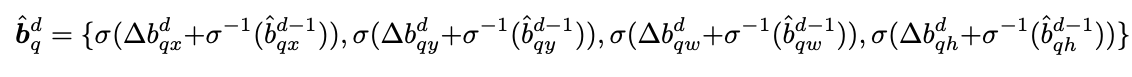
初始 BBox 中心点被设置为 $\hat p_{qx}$, $\hat p_{qy}$, 0.1, 0.1。
Two-Stage Deformable Detr
在两阶段的情形下,类似 FCN 文章对每个像素应用 Detection Head,会得到每个像素的预测框,然后选择 score 最大的一些框作为 BBox Refinement 的输入。 公式如下:
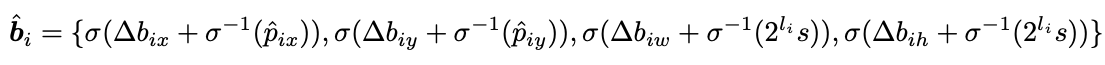
实验结果
见文章。
[^1]: Carion, N. et al. (2020) ‘End-to-End Object Detection with Transformers’. Available at: http://arxiv.org/abs/2005.12872.


